 Вход
ВходОпределение необходимого объема выборки. Как правильно рассчитать объем выборки
Определение объема выборки
Социологические исследования редко бывают сплошными, как, например, перепись населения. Обычно сплошное исследование проводится при небольшой генеральной совокупности.
Чаще всего исследования носят выборочный характер, при котором наиболее важным основанием является возможность распространения полученных результатов и выводов на всю генеральную совокупность. В таком случае сплошное исследование нецелесообразно. Обеспечение этой нецелесообразности - вопрос о репрезентативности выборки, т.е. достаточной количественной и качественной представительности генеральной совокупности в выборке.
Условиями соблюдения репрезентативности выборки являются:
1) равная возможность каждого члена генеральной совокупности попасть в выборку;
2) отбор необходимо проводить независимо от изучаемого признака (иначе в выборку могут попасть, например, только спортсмены);
3) отбор по возможности должен производиться из однородных совокупностей;
4) величина выборки должна быть достаточно большой.
Далее возникает вопрос: как определить достаточный объем выборки? Для этого необходимо иметь характеристики генеральной совокупности по важнейшим (с точки зрения исследования) признакам. К ним, например, можно отнести сведения о количестве желающих заниматься физической культурой и спортом, о числе занимающихся и т.д. Но, как правило, такие характеристики (или многие из них) не известны. Пилотажные исследования как раз и направлены на их выявление.
Приведем пример определения объема выборочной совокупности. В ходе подготовки к проведению конкретно-социологического исследования на основании теоретических посылок были выделены характеристики и признаки, подлежащие изучению. Например, желание заниматься физической культурой, спортом, величина потребности, участие в видах деятельности и др.
На основании результатов изучения этих признаков в пробном исследовании (30 и более респондентов) определяется объем выборки.
Предположим, что в пробном исследовании опрошено 147 студентов 4-х курсов в четырех вузах Республики Беларусь.
Для желания заниматься физической культурой получены следующие распределения:
1.«Нет, не хочу» - 5 человек;
2.«Скорее не хочу, чем хочу» - 3 человека;
3.«Безразлично» - 11 человек;
4.«Скорее хочу, чем не хочу» - 34 человека;
5.«Да, хочу» - 72 человека.
Для расчета объема выборки используются формулы:
t - 1,96 - распределение Стьюдента для вероятности 0,95 или 95% (т.е., если требуемая вероятность соответствия характеристик выборки и характеристик генеральной совокупности 95%, всегда = 1,96. Их соответствие на 95% - общепринятое требование в социологических исследованиях.
Для нашего распределения:

При условии, что выборка в пробном исследовании представляла бы собой модель генеральной совокупности, величина выборочной совокупности для изучения желания заниматься физической культурой должна быть не меньше 147 человек. Тогда с вероятностью 95% можно утверждать, что генеральное среднее лежит в пределах 4,39+ 0,155.
Поскольку модель выборки в пробном исследовании во вузам не представляет собой модели генеральной совокупности (опрос был в четырех вузах из 30), то увеличиваем полученное n (30/4) в 7,5 раза. Тогда необходимый объем выборки - 1102 респондента.
Качественная представительность полученной выборки оценивается сравнением существенных характеристик (либо связанных с существенными) генеральной совокупности и выборки. Для студенчества, например, такими характеристиками являются: соотношение по полу, охват учебными занятиями по физическому воспитанию, соотношение форм занятий и др.
Когда информация о признаках элементов генеральной совокупности отсутствует, исключается возможность определения объема выборочной совокупности при помощи формул. В этом случае можно опереться на многолетний опыт социологов - практиков, свидетельствующий о том, что для пробных опросов достаточна выборка объемом 100-250 человек. При массовых опросах, если величина генеральной совокупности 5000 человек, достаточный объем выборочной совокупности - не менее 500 человек, если же величина генеральной совокупности 5000 человек и более, то - 10% ее состава (но не более 2000-2500 человек). Это характеризует достаточно достоверные результаты исследования.
Расчет объема выборки
Из всех вопросов, которые задают сотрудникам знаменитого Института опросов общественного мнения Гэллапа, самым популярным является такой: как вы можете, проинтервьюировав 1000 человек, судить о том, что думают 250 млн американцев?
Для ответа на этот вопрос нужно упомянуть не только высокую квалификацию и огромный практический опыт сотрудников, но и использование ими статистики и математики. Если методы опроса не основаны на науке, результаты могут ввести вас в заблуждение.
В статистике приняты следующие разграничения объемов выборки. Объем выборки, достаточный для взаимопогашения случайностей и.получения статистических характеристик закономерного характера, равен 30. Выборка такого объема называется малой. Характер распределения значений признака в малых выборках приближается к нормальному с ростом числа испытаний. Минимальный объем выборки, позволяющий получить средние значения признака с указанием доверительных вероятностей, равен 5. Выборки такого объема называются сверхмалыми. Распределение значений признака в таких выборках характеризуется распределением Стьюдента. Но чаще всего в социологии имеют дело с гораздо большим объемом выборки.
При планировании выборочного обследования наступает момент, когда нужно решить, сколько человек опрашивать, т.е. каким должен быть объем выборки. Это решение чрезвычайно важно, поскольку слишком большая выборка потребует излишних затрат, а слишком маленькая понизит качество результатов.
Объем выборки - общее число единиц наблюдения, включенных в выборочную совокупность.
Поскольку выборочная совокупность - это часть генеральной совокупности, отобранная с помощью специальных методов, - важно, чтобы эта часть не искажала представления о целом, т.е. репрезентировала его. Социологов, часто проводящих эмпирические исследования, постоянно волнует вопрос о том, как много надо опрашивать человек, чтобы получить достоверную информацию? Институт Гэллапа в США проводит регулярные опросы по национальной выборке объемом в 1,5 тыс. человек и достигает поразительной точности (ошибка выборки составляет от 1 до 1,5%). Центр «Социо-Экспресс» Института социологии РАН проводит исследования на выборке объемом в 2 тыс. человек, при этом ошибка выборки не превышает 3% 31 .
Специалисты считают, что наилучшая выборка - не обязательно большая. Конечно, чем больше объем выборки, тем выше точность ее результатов. Однако даже огромная выборка не гарантирует успеха, если генеральная совокупность «плохо перемешана», т.е. является неоднородной. Однородной считается такая совокупность, в которой контролируемый признак распределен равномерно, не образует пустот или сгущений. В этом случае, опросив нескольких человек, можно получить точную информацию о распределении этого признака в генеральной совокупности.
Таким образом, на репрезентативность данных влияют не количественные характеристики выборочной совокупности (ее объем), а качественные характеристики генеральной совокупности - степень ее однородности.
В социологии еще не придумано единой и четкой формулы, используя которую можно рассчитать оптимальный объем выборочной совокупности, - такой формулы просто не существует в природе. И объясняется это весьма просто. Дело в том, что определение объема выборочной совокупности - проблема не столько статистическая, сколько содержательная. Иными словами, объем выборочной совокупности зависит от множества факторов, в том числе от целей и задач, теоретической модели, гипотез и методов исследования, степени однородности генеральной совокупности, наконец, требующейся точности получаемой информации.
Надо всегда помнить, что каждый процент прироста точности информации в исследовании приводит к резкому увеличению расходов на его проведение. Знаменитый институт Гэллапа, на протяжении многих десятилетий проводящий опросы в США, выявил, что при общенациональной выборке в 100 человек - ошибка выборки будет в пределах ±11%; 200 человек - ±8%; 400 - ±6%; 600 - ±5%; 750 -±4%; 1000 - ±4%; 1500 - ±3%; 4000 человек - ±2%. Именно поэтому он проводит общенациональные опросы в США на выборке в 1500- 2000 человек. Как видно, он предпочитает увеличение ошибки на 1% многократному увеличению стоимости исследования.
Практика показывает, что для многих социологов обоснование объема выборки является камнем преткновения, несмотря на значительное количество литературы, посвященной выборочным методам и, в частности, расчету объема выборки. Причин несколько: 1) дефицит специальной литературы на периферии; 2) нехватка времени для самообразования; 3) неумение пользоваться математическим аппаратом. В связи с этим возникает необходимость без сложных математических формул изложить стратегию и тактику обоснования объема выборки.
Процедура расчета объема выборки - цепь бесконечных компромиссов между стремлением к точности и ограниченностью ресурсов, дефицитом времени и неполнотой сведений об изучаемом явлении. Вместе с тем это наука и искусство, познание которых доступно каждому человеку. Однако для этого нужно знать стратегии расчета объема выборки (предварительного расчета, последовательной и комбинированной стратегии), а также факторы, влияющие на объем выборки (объем генеральной совокупности, варьирование ответов респондентов, точность оценивания, характер предполагаемого распределения ответов, метод исследования, процедура обработки).
Стратегия предварительного расчета состоит в том, что объем выборки определяется до проведения основного исследования. В наиболее простом случае можно воспользоваться уже наработанным опытом, например, института Гэллапа, где используется объем выборки приблизительно в 1500-2000 человек. Для среднестатистического отечественного исследования объема выборки - примерно 400-600 человек.
Для расчета объема случайной выборки надо знать желаемую точность оценивания, величину риска получаемого ответа и степень изменчивости ответа. Традиционно точность оценивания принимают за 5%, а величину риска - за 0,95. Иными словами, если по данным выборочного исследования 60% опрошенных удовлетворены работой, то можно утверждать, что в генеральной совокупности доля удовлетворенных составит от 55 до 65% в 95% случаев, а в 5% случаев такая доля может выйти за этот интервал. Если исходить из 5%-ной точности и величины риска в 0,95, объем выборки будет следующим (табл. 2.4).
Таблица 2.4 Зависимость объема выборки от объема генеральной совокупности
Результаты, приведенные в табл. 2.4, свидетельствуют против распространенного заблуждения, будто бы объем выборки - жестко фиксированный процент от генеральной совокупности, равный 10. На самом же деле эта величина - не постоянная, а переменная, изменяющаяся в конкретных условиях. Объем выборки зависит также от того, какие вопросы используются в анкете. Цифры в табл. 2.4 действительны только для одного случая - когда речь идет о дихотомическом вопросе, у которого максимальный разброс ответов - 50 на 50%. Не имея предварительной информации о разбросе оценок, социолог как бы заранее страхуется и считает, что этот разброс составит 50 на 50%. Если же такая информация имеется, то объем выборки будет следующим.
Таблица 2.5 Зависимость объема выборки от распределения дихотомического ответа
В табл. 2.5 показано распределение ответов на качественные вопросы. Расчет объема выборки для количественных вопросов, включающих вопросы типа «возраст» и «заработная плата», строится исходя из коэффициента вариации (табл. 2.6), который показывает, какой процент составляет среднее квадратическое отклонение от средней арифметической, и позволяет сравнивать между собой (по степени варьирования) любые признаки.
Таблица 2.6 Зависимость объема выборки от коэффициента вариации
| Коэффициент вариации, % | ||||||||||||
| Объем выборки |
Если изучаются условия труда, взаимоотношения в коллективе, заработная плата и т.д. с помощью пятичленной шкалы, то коэффициент вариации изменяется здесь от 27 до 62%, а при использовании семичленной - от 78 до 113%. Стало быть, чем длиннее шкала, тем выше коэффициент вариации и больше должен быть объем выборки. Если социолог хочет обойтись небольшой выборкой, то и вопросы должен формулировать проще. Иногда думают, что чем длиннее шкала, тем точнее измерение. Но преимущества семибалльных шкал над пятибалльными не доказаны.
Среди социологов распространено мнение, согласно которому чем больше объем выборки, тем точнее результат, и это заставляет их непомерно увеличивать количество опрошенных. В реальности дело обстоит иначе: табл. 2.7, составленная по данным Института Гэллапа, показывает зависимость между объемом выборки и точностью оценивания в процентах. Из нее следует, что с увеличением объема выборки точность возрастает, но до определенного порога. Уже при 600 опрошенных достигается желанный для всех 5%-ный уровень точности. Стало быть, 600 человек - приемлемый объем выборки.
Между цифрами 400 и 600 человек противоречия нет. В первом случае объем выборки рассчитывался, исходя из положения о нормальном распределении ответов респондентов, а во втором - из практики. Расхождение между теорией и практикой обусловлено тем, что в реальной ситуации распределение оценок отличается от нормального, поэтому объем выборки надо рассчитывать с учетом именно этого обстоятельства; наиболее эффективным способом уменьшения объема выборки является снижение коэффициента вариации оценок.
Таблица 2.7 Зависимость между объемом выборки и точностью оценивания
При расчете объема выборки социологи часто совершают такую ошибку: рассчитав по существующим формулам необходимый объем выборки в целом для совокупности, в дальнейшем пропорционально размещают его по отдельным подразделениям выборки, например по цехам, предприятиям, районам, городам, типам семей. После чего на этапе обработки данных - анализируют уже сами различия между подразделениями. Однако правильнее вычислить объем выборки отдельно для каждого подразделения, а)атем суммировать отдельные объемы. Допустим, расчеты объема выборки по трем цехам (с учетом размерности шкалы, численности работающих, характера предполагаемого распределения оценок) позволили установить, что в первом цехе необходимо спросить 384 человека, во втором - 222, а в третьем - 600. Тогда общий объем выборки составит 384 + 222 + 600 = 1206 человек.
Если социологу необходимо опросить какую-либо категорию работников (допустим, водителей автобусов), о которой известно лишь, что к ней принадлежит, например, десятый работник предприятия, и он решил спросить 139 водителей автобусов, а общий объем выборки для предприятия составит 1390 человек, т.е. иными словами, отбирая случайным образом 1390 респондентов на предприятии, мы в соответствии с теорией выборки надеемся выявить 139 человек интересующей нас специальности.
При расчете квотной выборки социологи часто произвольно определяют ее объем в 1000 человек, исходя из удобства вычисления квот. Но с таким же успехом можно взять любое другое круглое число. Более обоснованным является подход, при котором объем квотной выборки рассчитывается как для случайной. Другим вариантом расчета объема квотной выборки является использование теории малых выборок. Ее суть: если не ставится цель дать дифференцированный анализ по группам работников, то умножают количество градаций вопросов, подлежащих изучению, на 25 (минимальный статистический значимый размер группы). Например, изучают три переменные: пол - две категории, возраст - две категории (до 30 лет и свыше 30 лет), удовлетворенность трудом - измеряется пятибалльной шкалой. Тогда необходимый объем выборки для данного примера составит 2x2x5x25 = 500 человек. Объем выборки увеличивается в 2,5 раза. Ясно, что с расширением числа переменных и числа градаций объем выборки может стать катастрофически большим. Выход только один: детальная проработка исходной проблемы, которая позволит отбраковать лишние вопросы в анкете, оставив самые важные. Если в исследовании проверяется несколько гипотез, то объем выборки для проверки каждой гипотезы вычисляется отдельно. Таким образом, при использовании выборки количество вопросов в анкете и гипотез должно быть минимальным.
Итак, мы рассчитали требуемый объем выборки. Теперь, и только теперь необходимо проверить, совместима ли полученная величина с выделенными ресурсами. Типичная ошибка многих социологов-прикладников состоит в том, что при расчете объема выборки во главу угла ставятся наличные ресурсы или, хуже того, социолог пассивно принимает все условия, диктуемые заказчиком. Это в корне неверно по нескольким причинам. Во-первых, расчет объема выборки позволяет глубже проникнуть в суть изучаемого предмета и специфику методов исследования, а значит, аргументированно требовать получения больших ресурсов или принять правильное решение о снижении объема выборки. Если администрация отказала в дополнительных ресурсах, а цели исследования не позволяют сократить объем выборки (т.е. социолог не может принять решение администрации), то надо переходить к другой схеме исследования. Во-вторых, обоснованный расчет объема выборки показывает профессионализм социолога и заставляет заказчика относится к нему более уважительно.
Стратегия последовательного расчета объема выборки. При расчете объема выборки желательно знать разброс оценок и некоторые другие параметры. Однако они-то, как правило, неизвестны. Для того чтобы не допустить ошибки, лучше предположить, что они максимальны. Плата за наше незнание - разбухание объема выборки сверх необходимого и дополнительные финансовые и временные затраты (приходится опрашивать большее число людей). Для сохранения затрат применяется последовательная стратегия - объем выборки не рассчитывается заранее, а ставится в зависимость от конечных результатов исследования. Например, опрашивают 100 человек, затем устанавливают величину разброса оценок и уже в зависимости от этого рассчитывают необходимый объем выборки. Если оказывается, что 100 человек достаточно, то исследование заканчивается. В противном случае добирается необходимое количество респондентов, но не до бесконечности. Известен пример из практики Дж. Гэллапа, который в начале своей карьеры активно экспериментировал с объемами выборки. В 1936 г. американцам был задан вопрос: «Хотели бы вы возобновления закона о восстановлении национальной промышленности?» Выяснился странный парадокс: Дж. Гэллап вначале опросил 500 человек и замерил ошибку выборки, а затем последовательно наращивал число респондентов до 30 тыс. К своему сожалению, он обнаружил, что прибавление 29,5 тыс. опрошенных увеличило точность информации менее чем на 1%. Следовательно, опрос можно было прекращать уже при 500 опрошенных. Этот пример показывает, что, применяя последовательную стратегию, можно добиваться значительного снижения необходимого числа наблюдений по сравнению с предварительным расчетом объема выборки.
Однако стратегия последовательного расчета объема выборки приносит желаемый результат лишь в том случае, если социолог может производить необходимые расчеты в ходе самого опроса, например телефонного, с применением компьютерных систем. Социолог вводит ответы респондента в свой персональный компьютер, с него результаты сразу поступают на компьютер руководителя исследования, обрабатываются, и на экране дисплея выдается информация не только об одномерных частотах, распределенных по тому или иному вопросу, но и о требуемом объеме выборки.
Если существует опасность, что объем выборки может оказаться катастрофически большим, надо совместить оба вида стратегии - предварительную и последовательную, т.е. применить комбинированную стратегию. Рассчитывая выборку по предварительной стратегии, получаем верхние допустимые значения для последовательной стратегии или, иначе говоря, ту величину объема выборки, при достижении которой прекращается опрос по последовательной стратегии.
Наиболее обоснованный и корректный подход к определению объема выборки основан на расчете доверительных интервалов, в основе которого лежит ряд базовых понятий математической статистики (вариация, среднее квадратическое отклонение, доверительный интервал, средняя квадратическая ошибка).
Для расчета необходимого размера выборки в количественном исследовании чаще всего используют два статистических понятия - доверительный интервал и доверительную вероятность. Доверительный интервал представляет собой заранее задаваемую вами погрешность выборки. Например, если вы задаете доверительный интервал в 3% и конкретный ответ на конкретный вопрос исследования составит 48%, это значит, что даже при проведении опроса всей генеральной совокупности реальное значение попадет в интервал между 45 (48 - 3) и 51% (48 + 3). Доверительная вероятность показывает, насколько вы можете быть уверены в полученных результатах, в том, что характеристики выборки соответствуют характеристикам всей генеральной совокупности - иными словами, с какой вероятностью случайный ответ попадет в доверительный интервал. Обычно используют доверительную вероятность 95 и 99%. Чаще всего используется 95% - этого вполне достаточно в подавляющем большинстве исследований. Если объединить доверительную вероятность и доверительный интервал, то можно сказать, что ответы на вопрос с 95%-ной вероятностью попадут в интервал между 45 и 51%.
Весьма полезна следующая приблизительная оценка надежности результатов выборочного обследования. Повышенная надежность допускает ошибку выборки до 3%, обыкновенная - от 3 до 10% (доверительный интервал распределений на уровне 0,03- 0,1), приближенная - от 10 до 20%, ориентировочная - от 20 до 40%, а прикидочная - более 40%.
На основе этих понятий с учетом ряда предположений выводятся формулы расчета объема выборки, которые предполагают, что репрезентативность гарантируется путем использования корректных вероятностных процедур формирования выборки.
В ряде случаев в качестве главного аргумента при определении объема выборки используется стоимость проведения обследования. Так, в бюджете маркетинговых исследований предусматриваются затраты на проведение определенных обследований, которые нельзя превышать, и очевидно, что ценность получаемой информации не принимается при этом в расчет. Однако в ряде случаев и малая выборка может дать достаточно точные результаты.
Исследовательская практика подсказывает следующее правило: объем выборки должен обеспечивать не менее 100 наблюдений для каждой первостепенной и не менее 20-50 наблюдений для каждой второстепенной классификационной составляющей. 11ервостепенные классификационные составляющие соответствуют наиболее критичным, а второстепенные - наименее критичным ячейкам перекрестной классификации, принятой в данном исследовании 34 . Теоретические расчеты и практика доказывают, что для получения достоверных данных о мнении и предпочтениях населения такого крупного города, как Санкт-Петербург, достаточно опросить 700-800 человек. Однако большинство опросов населения здесь проходят на выборках объемом до 1,5 тыс. человек.
Ошибка выборки
Как мы уже знаем, репрезентативность - свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности - мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной - 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями - генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой - «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки - отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными».
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа - случайные и систематические. Случайная ошибка - это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности (табл. 2.8).
Таблица 2.8
Зависимость объема выборки от ее ошибки 36 (размер генеральной совокупности составляет 20 тыс. ед.)
| Ошибка выборки, % | |||||||||||||
| Объем выборки, ед. |
Второй тип ошибок выборки - систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки - результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например: 1) выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд); 2) налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%); 3) отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
♦ нарушены методические и методологические правила проведения социологического исследования;
♦ выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
♦ произошла замена требуемых единиц наблюдения другими, более доступными;
♦ отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее - в самом начале исследования.
Вот некоторые способы избежать ошибок:
♦ каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
♦ отбор желательно производить из однородных совокупностей;
♦ надо знать характеристики генеральной совокупности;
♦ при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, характеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностью. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ - увеличивать размеры выборки (и идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь - совершенствовать математические методы составления выборки. Они-то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал - математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже - тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов: I) стоимости сбора информации и 2) стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь. Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны помученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, - 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно (гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки (табл. 2.9):
Таблица 2.9
Расчеты репрезентативной выборки
Это означает, что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной 39 вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33±5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки (см. выше).
Сегодня многие трудные расчеты берет на себя техника, а статистические программы можно получить по Интернету. Вот и с расчетом выборки ленивому социологу предоставили такую возможность на веб-сайте Аналитического центра «Бизнес и маркетинг» (http://www.bma.ru/enter.htm), где пользователю надо лишь внести необходимые данные, а затем нажать на кнопку «Рассчитать».
Интервальное оценивание вероятности события. Формулы расчета численности выборки при собственно-случайном способе отбора.Для определения вероятностей интересующих нас событий мы применяем выборочный метод : проводим n независимых экспериментов, в каждом из которых может произойти (или не произойти) событие А (вероятность р появления события А в каждом эксперименте постоянна). Тогда относительная частота p* появлений событий А в серии из n испытаний принимается в качестве точечной оценки для вероятности p появления события А в отдельном испытании. При этом величину p* называют выборочной долей появлений события А , а р - генеральной долей .
В силу следствия из центральной предельной теоремы (теорема Муавра-Лапласа) относительную частоту события при большом объеме выборки можно считать нормально распределенной с параметрами M(p*)=p и
Поэтому при n>30 доверительный интервал для генеральной доли можно построить, используя формулы:

где u кр находится по таблицам функции Лапласа с учетом заданной доверительной вероятности γ: 2Ф(u кр)=γ.
При малом объеме выборки n≤30 предельная ошибка ε определяется по таблице распределения Стьюдента :
![]() где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
где t кр =t(k; α) и число степеней свободы k=n-1 вероятность α=1-γ (двустороння область).
Формулы справедливы, если отбор проводился случайным повторным образом (генеральная совокупность бесконечна), в противном случае необходимо сделать поправку на бесповторность отбора (таблица).
Средняя ошибка выборки для генеральной доли
| Генеральная совокупность | Бесконечная | Конечная объема N |
| Тип отбора | Повторный | Бесповторный |
| Средняя ошибка выборки |
Формулы расчета численности выборки при собственно-случайном способе отбора
| Способ отбора | Формулы определения численности выборки | ||
| для средней | для доли | ||
| Повторный | |||
| Бесповторный | |||
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p 0 ?» - можно ответить, проверив статистическую гипотезу H 0:p=p 0 . При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p * появления события A: где m - количество появлений события А в серии из n испытаний. Для проверки гипотезы H 0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).Таблица 1 - Гипотезы о генеральной доле
Гипотеза | H 0:p=p 0 | H 0:p 1 =p 2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  | 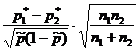 |
| Распределение статистики K | Стандартное нормальное N(0,1) |
Пример №1
. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал , с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
![]()
Значение u кр находим по таблице функции Лапласа из соотношения 2Ф(u кр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при u кр =1.96. Следовательно, предельная ошибка ![]() и искомый доверительный интервал
и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2
. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение
. Выборочная доля «удачных» дней составляет
По таблице функции Лапласа найдем значение u кр при заданной
доверительной вероятности
Ф(2.23) = 0.49, u кр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40 , N = 365 (дней). Отсюда ![]()
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3
. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01 ?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4
. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение
. Сформулируем основную и альтернативную гипотезы.
H 0:p=p 0 =0,97 - неизвестная генеральная доля p
равна заданному значению p 0 =0,97. Применительно к условию - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H 1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K
(таблица) вычислим при заданных значениях p 0 =0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-K kp)= (-∞;-2,05). Наблюдаемое значение К набл =-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5
. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода - 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение K набл =2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
Объем выборки - это количество единиц выборочной совокупности, которые нужно изучить. Необходимый объем выборки может быть определен на основе качественных и количественных характеристик.
Среди наиболее значимых качественных факторов, определяющих объем выборки, можно назвать :
- важность принимаемого решения. Как правило, для принятия важных решений необходима детальная, максимально точная информация. Ее получение предусматривает создание больших выборок, но при увеличении объема выборки возрастает и стоимость получения каждой дополнительной единицы информации;
- характер исследования. На величину объема выборки влияет также характер исследования. В поисковых исследованиях, изучающих качественные характеристики респондентов, объем выборки, как правило, невелик. Для исследований, предусматривающих статистическую обработку собранных данных, таких как дескриптивные, необходим больший объем выборки;
- количество переменных. Кроме того, большие выборки нужны, когда информация собирается с учетом большого количества переменных. Большой объем выборки позволяет снизить общий эффект от ошибок выборки по всем переменным;
- характер анализа и уровень детализации. Большой объем выборки необходим при проведении углубленного анализа данных с использованием разнообразных методов многомерного статистического анализа. Это же касается и ситуации, когда надо провести анализ не только в целом по выборке, но и в разрезе отдельных групп (например, мужчины и женщины, возрастные группы, тип населенного пункта);
- ограниченность ресурсов. Принимая решения об объеме выборки, необходимо учитывать временные, финансовые и кадровые ресурсы;
- объем выборки в аналогичных исследованиях. Наконец, на величину объема выборки влияет типичный объем выборок, используемых в аналогичных исследованиях. В случае, если на каком-то рынке проводятся ежегодные исследования, то используется выборка одного и того же объема (панели).
Табл. 8 дает представление об объемах выборок, используемых в различных маркетинговых исследованиях. Эти величины установлены опытным путем и могут использоваться в качестве ориентировочных данных, особенно при детерминированных методах формирования выборки .
Таблица 8
Типичный размер выборок для конкретных видов исследования
|
Предмет исследования |
Минимальный размер |
Типовой размер, чел. |
|
Изучение рынков |
1000-1500 чел. |
|
|
Стратегическое исследование |
||
|
Внедрение на рынок - тест |
||
|
Тестирование товара |
||
|
Тестирование названия |
||
|
Тестирование упаковки |
||
|
Целевая группа |
8-12 регион |
Объем выборки может определяться на основе статистического анализа. Этот подход основан на определении минимального объема выборки исходя из конкретных требований к надежности и достоверности получаемых результатов.
Статистический расчет объема и ошибки выборки можно выполнить только для вероятностных выборок, для неверо ятностных выборок статистические методы расчета объема и ошибки выборки неприменимы.
Для расчета объема выборки необходимо иметь следующие данные:
- 1. Заданный размер доверительной вероятности Р и коэффициент доверия t, зависящий от принятой вероятности (определяется эмпирически или на основе справочной таблицы функции Лапласа).
- 2. Величину выборочного стандартного отклонения s^ ж S y , которая вычисляется либо принимается исходя из предшествующих исследований или пробных выборок.
- 3. Стандартное отклонение, или меру степени разброса значений случайной величины относительно среднего. Оно может быть определено с использованием правила “трех сигм”, или исследователь может определить величину диапазона исходя из собственного понимания анализируемого явления. Например, задать величину максимально допустимой ошибки при оценке средней цены товара ±5 руб., а для доли респондентов, предпочитающих определенную марку товара, ±0,05%.
- 4. Объем генеральной совокупности. Расчет объема выборки проводится с учетом типа выборки (простая, кластерная и пр.) и с использованием статистических программных средств или на основе формул математической статистики.
Пример 33. Допустим, необходимо провести маркетинговое исследование рынка автокресел для детей. Известно, что количество детей от 0 до 5 лет в регионе составляет 100 тыс. человек. Доверительная вероятность равна 95,4% (t=2), стандартное отклонение на основе предыдущих аналогичных исследований принято равным 100 и желаемая точность (погрешность) составляет ±10. Определить объем выборки. Используем формулу расчета объема простой случайной выборки при бесповторном отборе
Пример 34. Проведем расчет выборки для маркетингового исследования, посвященного узнаваемости потребителями торговой марки. Значение вероятности Р = 0,954, предельно допустимая ошибка данного исследования не должна превышать 5%. Какое количество респондентов необходимо опросить для решения этой проблемы в порядке случайной повторной выборки притом, что данные о распределении признаков отсутствуют?
Так как доля признака неизвестна, допустим, что 50% потребителей знают торговую марку, а 50% - нет.
Используем формулу расчета выборки с учетом доли признака:
Приведенная ниже формула для расчета объема выборки используется в тех случаях, когда опрашиваемым (респондентам) задается только один вопрос, на который существует только два варианта ответа. Например, «Да» и «Нет»; «Пользуюсь» и «Не пользуюсь». Конечно, данную формулу можно применять только при проведении простейших исследований. Если Вам нужно определить объем выборки при проведении более масштабных исследований, например анкетирования, то следует использовать другие формулы.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный - доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p - это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96 . Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они - «Да». Тогда p = 0,5 . Отсюда находим q = 1 – p = 1 – 0,5 = 0,5 . Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1 .
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек .
Область применения данной формулы
При проведении простых исследований, когда нужно получить ответ всего на один простой вопрос. При этом шкала ответов, как правило, дихотомического характера. То есть предлагаются (или подразумеваются) варианты ответов по типу «Да» - «Нет», «Черное» - «Белое», и т.д.
Особенности данной формулы расчета объема выборки
Галяутдинов Р.Р.
© Копирование материала допустимо только при указании прямой гиперссылки на